GENERATING STEREOPHONIC MUSIC WITHSINGLE-STAGE LANGUAGE MODELS
Xingda Li, Fan Zhuo, Dan Luo, Jun Chen, Shiyin Kang, Zhiyong Wu, Tao Jiang, Yang Li, Han Fang, Yahui Zhou
[Paper] Submitted to ICASSP 2023.
Abstract
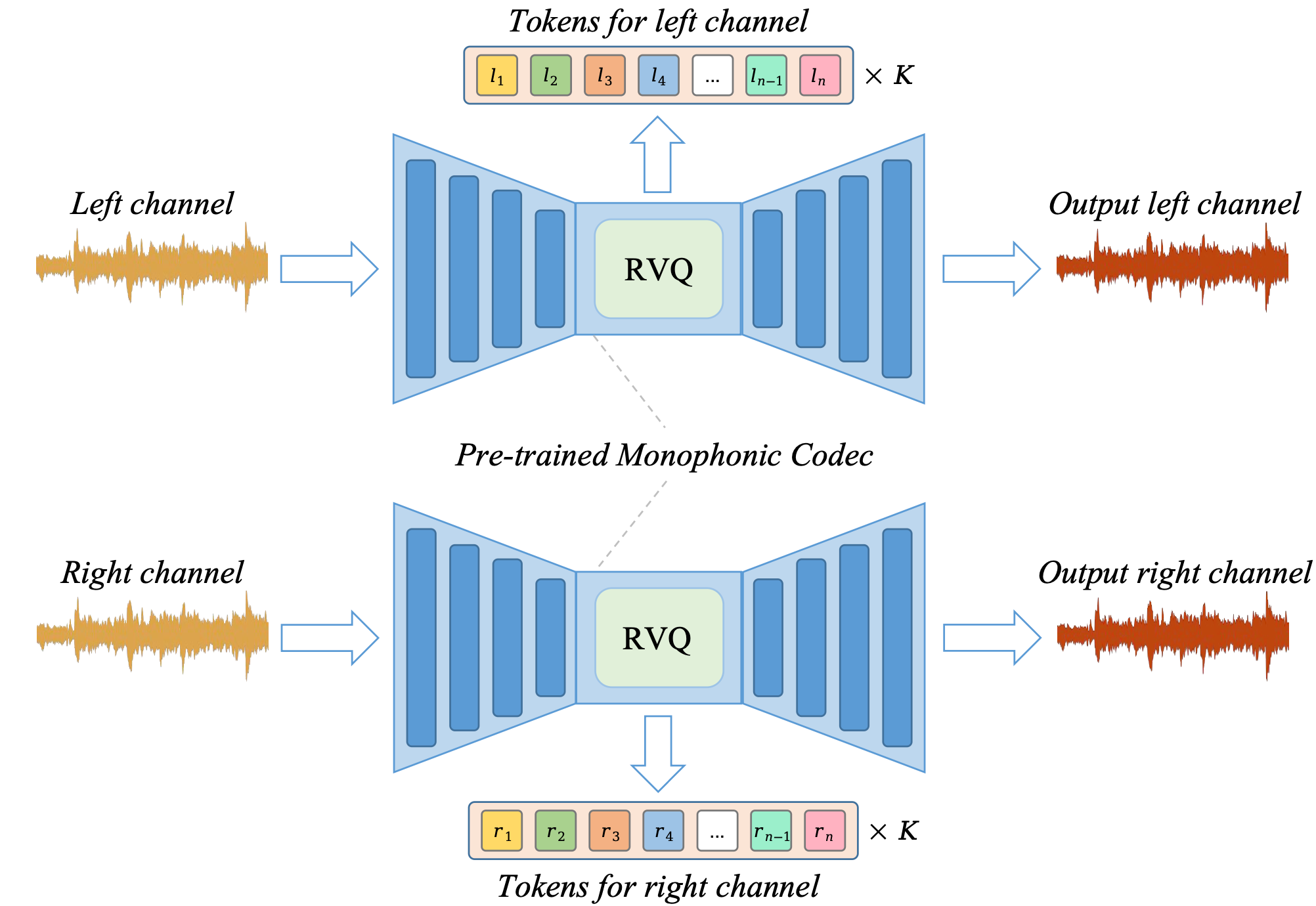
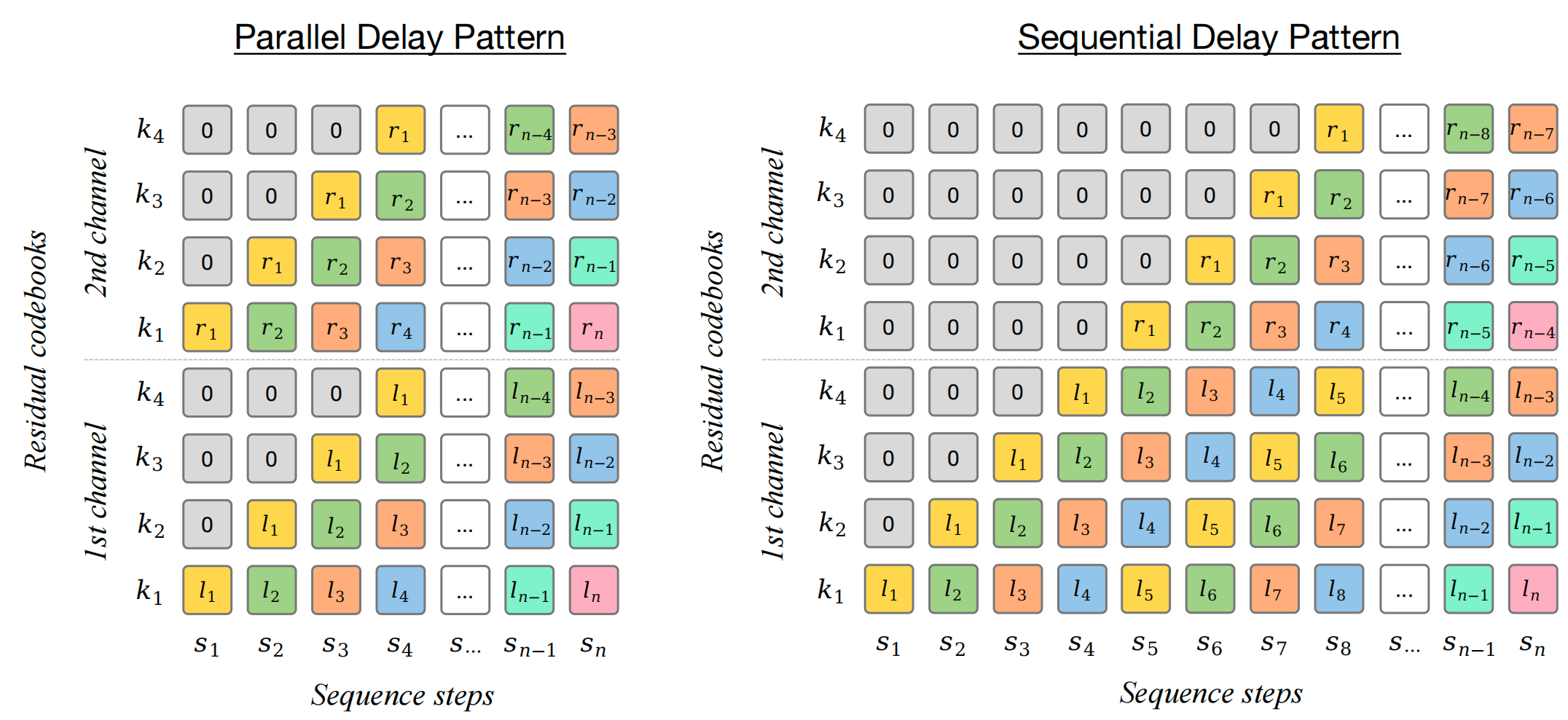
The recent success of audio language models (LMs) has revolutionized the field of neural music generation. Among all audio LM approaches, MusicGen has demonstrated the success of a single-stage LMs based music generation framework, without needing to train multiple LMs. Despite its promising performance in generating monophonic (mono) music, directly generating stereophonic (stereo) music following the previous framework has resulted in perceptible quality degradation. In this paper, we first discuss the difficulty of directly encoding stereo music with neural codec, and then provide a stable and practical solution based on a dual encoding approach. To utilize the dually encoded tokens in single-stage LMs, we also propose two forms of token sequence patterns. An extensive evaluation has been conducted using various aspects of stereo music audios to examine the performance of stereo neural codec approaches and the generation quality of single-stage LMs. Finally, our experimental results suggest that (i) our proposed dual encoding approach for neural codec is significantly better than the typical joint encoding approach in terms of reconstruction quality, and (ii) the stereo single-stage LMs trained with our proposed token sequence patterns substantially improved the perceptual quality over the state-of-the-art music generation model (i.e. MusicGen) in subjective tests.